


The concept of data observability has emerged as a critical strategy for maintaining data integrity, reliability, and performance. This article explores the fundamental principles of data observability and its transformative potential.
What is Data Observability?
Data observability is more than just monitoring – it's about gaining unprecedented visibility and control over your entire data ecosystem. It encompasses a range of practices and tools designed to provide insights into data quality, reliability, and performance. Core data observability activities include:
- Monitoring: Continuous oversight of data pipelines to detect anomalies and ensure timely data delivery.
- Alerting: Automated notifications about potential issues, enabling proactive resolution.
- Data tracking: Process of choosing specific metrics and events, then collecting, categorizing, and analyzing those data points throughout the data pipeline for the purpose of analysis.
- Data Replication Testing: Ensuring that migrated or replicated data maintains its accuracy and functionality.
How does data observability fit into the modern data stack**?**
Data observability is vital for keeping the enterprise data stack running as a well-oiled machine rather than a clunky collection of poorly integrated tools. As the modern stack continues to grow and become more complex data, data observability is essential for maintaining quality and keeping a steady flow of data throughout daily business operations. Here are some key impact on businesses:
- Improved Data Quality: By continuously monitoring data flows and validating inputs, organizations can reduce errors and improve the overall quality of their datasets. This leads to more reliable insights for strategic decisions.
- Faster Issue Resolution: With real-time alerts and automated testing, businesses can identify and rectify data issues before they escalate, minimizing downtime and operational disruptions.
- Enhanced Trust in Data: As organizations gain confidence in their data's accuracy, stakeholders—ranging from executives to front-line employees—can make informed decisions based on reliable information.
Examples:
How Meta is Scaling Data Integrity Across Billions of Users:
Meta's data infrastructure is designed to manage unprecedented volumes of user data, making observability essential to their operations.
The company manages over 2.9 billion monthly active users, processes more than 4 petabytes of data daily, and maintains data integrity across 200+ global data centers. Handling such vast amounts of data is challenging, and requires a robust framework to minimize errors.
To ensure data integrity, Meta has implemented several key strategies:
- Custom-built data monitoring frameworks: These frameworks allow Meta to continuously track the health and performance of their data systems.
- Automated data validation across multiple global data centers: This ensures that data remains consistent and reliable, regardless of its location.
- Advanced anomaly detection algorithms: These algorithms help identify unusual patterns or discrepancies in user data, enabling rapid response to potential issues.
Uber has developed an in-house data observability platform called M3, designed to handle the massive quantities of data generated by its operations. M3 serves as a large-scale metrics engine that processes 600 million data points per second, enabling Uber to monitor critical business metrics effectively.
Spotify uses Apollo, its in-house data observability platform, to monitor user interactions, optimize recommendations, and maintain smooth streaming experiences for its over 456 million active users globally. Apollo processes billions of events daily, playing a crucial role in improving user engagement and maintaining performance at scale
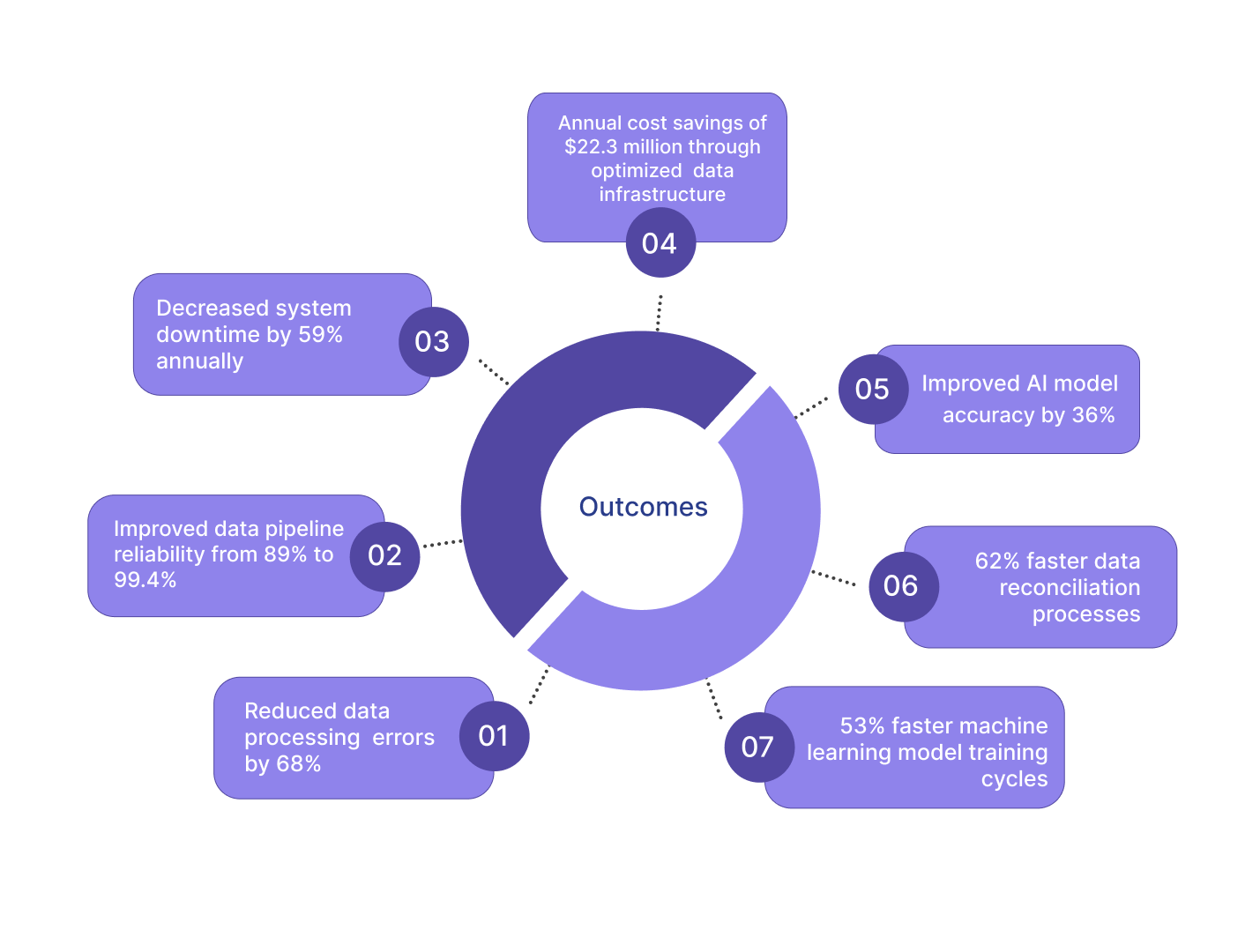
The Shift to Observability
The transition from traditional monitoring to comprehensive data observability represents a paradigm shift in how organizations manage their data. Traditional methods often involve reactive approaches that lack the depth needed to understand complex data interactions. In contrast, data observability provides richer context and insights into the complexities of data ecosystems, allowing organizations to anticipate disruptions before they impact operations.
Platforms like Datachecks provide automated tools exemplifies a modern data observability platform that automates monitoring processes while providing organizations with essential tools for testing their data.
Conclusion
In conclusion, as enterprises continue to accumulate vast amounts of data, implementing effective data observability practices becomes essential for maintaining high standards of accuracy and reliability. This proactive approach not only enhances operational efficiency but also positions organizations to leverage their data assets strategically for sustained competitive advantage.
Subscribe to the Datachecks Newsletter and join a community of forward-thinking professionals. Get the latest insights, best practices, and exclusive updates delivered straight to your inbox. Sign up now!









