

Organizations process petabytes of data daily. However, the real challenge isn’t just moving data — it’s ensuring its reliability, accuracy, and trustworthiness throughout its journey. A recent study by Gartner revealed that organizations lose an average of $12 million per year due to poor data quality. The increasing complexity of data ecosystems, combined with the growing demand for real-time insights, makes building trustworthy data pipelines more crucial than ever.
The Data Trust Crisis
Consider a sobering scenario: A major e-commerce platform’s recommendation system started showing irrelevant products to users. The root cause? Undetected data quality issues in their user behavior pipeline. The result was a 23% drop in click-through rates and an estimated revenue loss of $3 million before the issue was identified and fixed. This isn’t an isolated incident — it’s a symptom of insufficient data pipeline oversight.
Understanding Pipeline Trust Factors
Trust in data pipelines is built on three fundamental pillars:
Data Quality
Data quality encompasses accuracy, completeness, and consistency. For instance, a financial services company processes millions of transactions daily. Each transaction must maintain its integrity from source to destination. This means a $100 transfer should remain $100 throughout the pipeline, with all associated metadata intact and accurate.
Pipeline Reliability
Reliability ensures that data moves predictably and consistently through your system. When Netflix processes viewing data to generate recommendations, their pipeline must handle both regular traffic and sudden spikes during popular show releases. A reliable pipeline adapts to these varying loads while maintaining data integrity.
Data Observability
Observability gives you visibility into your pipeline’s health and performance. Amazon’s supply chain management system, for example, tracks millions of products across warehouses. Their observability systems monitor data freshness, completeness, and accuracy in real-time, enabling quick detection and resolution of issues.
Building Trust Through Architecture
A trustworthy data pipeline requires thoughtful architecture that incorporates several key elements:

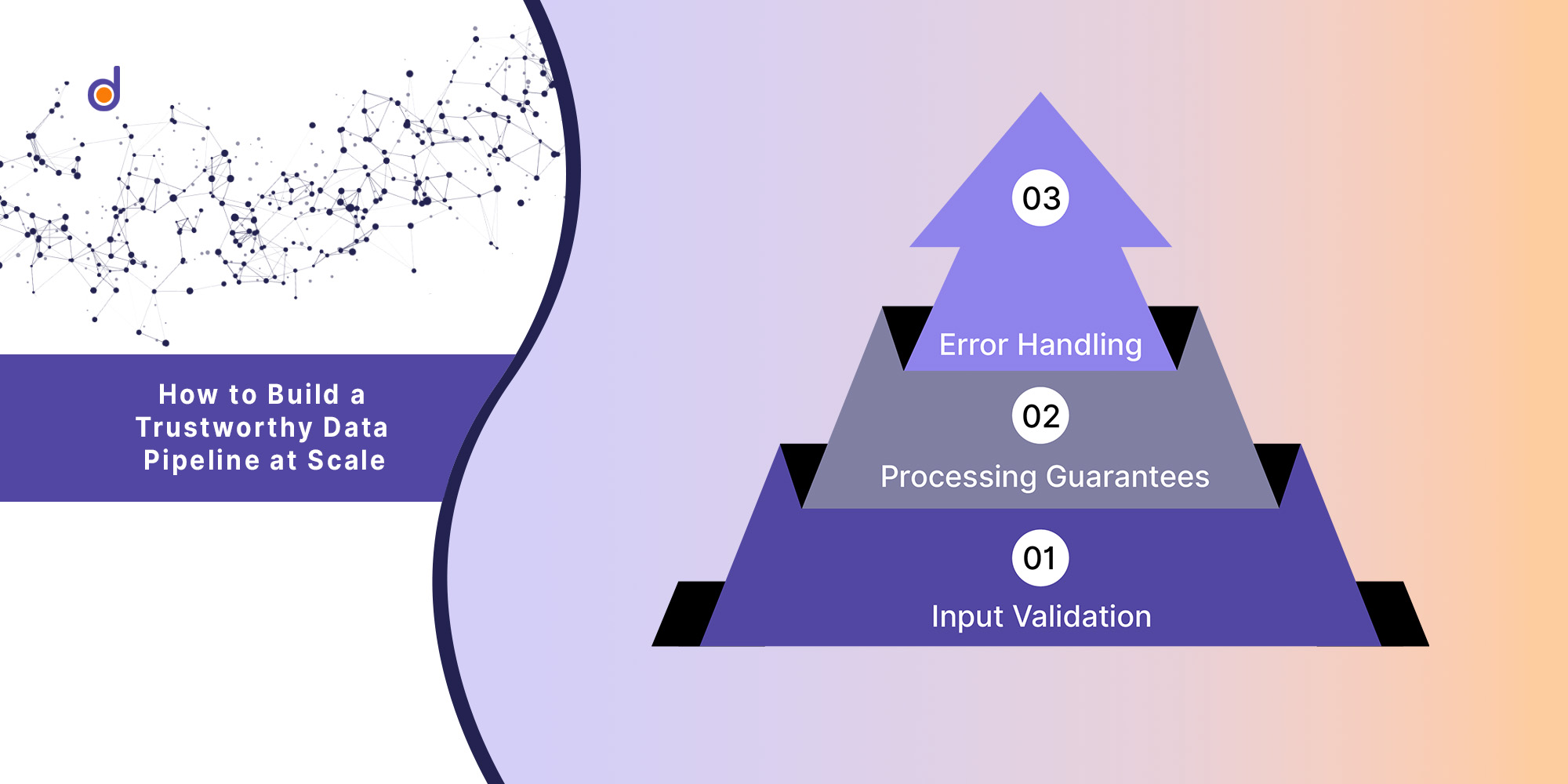
1. Input Validation
Every data point entering your pipeline should be validated. Take Uber’s ride-tracking system: it validates location data in real-time, ensuring coordinates are within reasonable bounds and follow expected patterns.
2. Processing Guarantees
Your pipeline should provide clear processing guarantees. Stripe’s payment processing pipeline, for instance, ensures exactly-once processing of transactions, preventing double-charges or missed payments.
3. Error Handling
Robust error handling is crucial. LinkedIn’s member data pipeline has sophisticated error recovery mechanisms that prevent data loss even during system failures.
The Role of Data Observability
Data observability acts as your pipeline’s nervous system, providing real-time insights into:
Health Metrics
Monitor processing times, error rates, and system resource usage. For example, Airbnb’s booking pipeline tracks processing latency to ensure real-time updates of property availability.
Data Quality Metrics
Track accuracy, completeness, and consistency of data. A retail chain’s inventory management system monitors these metrics to prevent stockouts and overstock situations.
Lineage Tracking
Understand how data transforms as it moves through your pipeline. Google’s advertising platform uses lineage tracking to ensure compliance with privacy regulations and audit requirements.
Impact of Modern Data Observability Platforms
Organizations implementing comprehensive data observability platforms like Datachecks can monitor their data pipelines in real-time, catching potential issues before they escalate. This proactive monitoring ensures data flows as intended, alerts teams the moment any irregularity is detected.
Before Integrating Observability
- Average time to detect issues: 12 hours
- Data quality issues discovered by end users: 60%
- Annual loss from data-related incidents: $1M+
After Integrating Observability
- Average detection time: 5 minutes
- Issues caught before reaching users: 95%
- Reduction in data-related losses: 85%
Future-Proofing Your Pipeline
The future of data pipelines lies in intelligent observability. Modern systems are incorporating:
AI-Powered Monitoring
Machine learning models that predict potential issues before they occur. For example, PayPal uses AI to detect anomalies in transaction patterns that might indicate data pipeline issues.
Automated Remediation
Self-healing capabilities that can automatically resolve common issues. Microsoft’s cloud services use automated remediation to maintain data pipeline health without human intervention.
Way Ahead
Building trustworthy data pipelines at scale requires more than robust architecture — it demands comprehensive observability. Organizations must shift from reactive to proactive data management. The key takeaways are:
As data continues to grow in volume and importance, the ability to trust your data pipeline becomes a critical business advantage. Remember: in the world of big data, being able to move data is just the beginning. Being able to trust it is what sets successful organizations apart.’
Sign Up for Datachecks Newsletter to stay updated on latest Data Quality Trends & Best Practices.









